
Twój MVP działa. Pierwsze zapisy spływają, kilka osób pyta o demo. Zespół świętuje. Trzy miesiące później przychodzi pierwszy poważny klient — chce integrację z ich systemem, SSO, eksport do CSV. Siadasz do kodu i nagle okazuje się, że ten „szybki skrót", który oszczędził wam 80 godzin na start, teraz zajmie 400 godzin refaktoru. Witaj w produkcyjnej fazie MVP.
Kluczowe wnioski z artykułu:
- 90% startupów upada; 67% z nich buduje coś, czego nikt nie chciał — MVP to NIE jest budowa produktu, to walidacja hipotezy
- Zespoły z wysokim długiem technicznym dostarczają funkcje o 40% wolniej (McKinsey 2025) — skrót z dnia 1. płaci Ci odsetki przez lata
- 33-42% czasu programisty pożera dług techniczny — Stripe szacuje $85 mld rocznie straconej produktywności globalnie
- Do Roku 3 skrót, który zaoszczędził 80 godzin, kosztuje Cię 380 godzin poprawek
- Skalowanie przed Product-Market Fit = największa pułapka — 70% firm umiera między 2. a 5. rokiem właśnie z tego powodu
MVP to nie „minimalna wersja produktu". To eksperyment.
Największe nieporozumienie w startupach: „zbudujemy MVP, potem go rozbudujemy". Słowo MVP znaczy Minimum Viable Product. Akcent pada na „Viable" — żywotne, zdolne do życia. Nie „gotowe do skalowania". Nie „fundament produktu". Żywotne dla eksperymentu.
MVP istnieje po to, żeby sprawdzić, czy ktoś będzie tego używał. Kropka. To jest sonda wysłana w kosmos — ma przetrwać wystarczająco długo, żeby przesłać dane, ale nie planujesz na niej wozić ludzi na Marsa. Badanie startupów z lat 2024-2025 pokazuje jednoznacznie: 67% porażek wynika z faktu, że zespoły budowały coś, czego nikt nie chciał. Nie ze złego kodu. Nie ze złej architektury. Z braku walidacji.
Pisałem o tym w kontekście różnicy między budowaniem produktu a rozwiązywaniem problemów. MVP należy do drugiej kategorii. Jeśli traktujesz go jak pierwszą — już przegrałeś.
Dlaczego 70% startupów umiera między rokiem 2. a 5.
Nie dlatego, że wygasają pieniądze. Nie dlatego, że konkurencja jest lepsza. Dlatego, że skalują przed osiągnięciem Product-Market Fit. Widzą pierwszą trakcję — 100 userów, 1000 rejestracji — i decydują: „teraz jedziemy". Zatrudniają, wydają na marketing, rozbudowują team sprzedaży.
Sześć miesięcy później odkrywają, że churn jest wyższy niż acquisition. Ludzie się zapisują. Ludzie nie zostają. Pisałem o fałszywym Product-Market Fit — gdy zainteresowanie bierzesz za dopasowanie. Tu jest to samo, ale z dodatkową warstwą długu technicznego. Bo skalowanie zbudowane na fundamencie MVP = fundament pęka pierwszy.
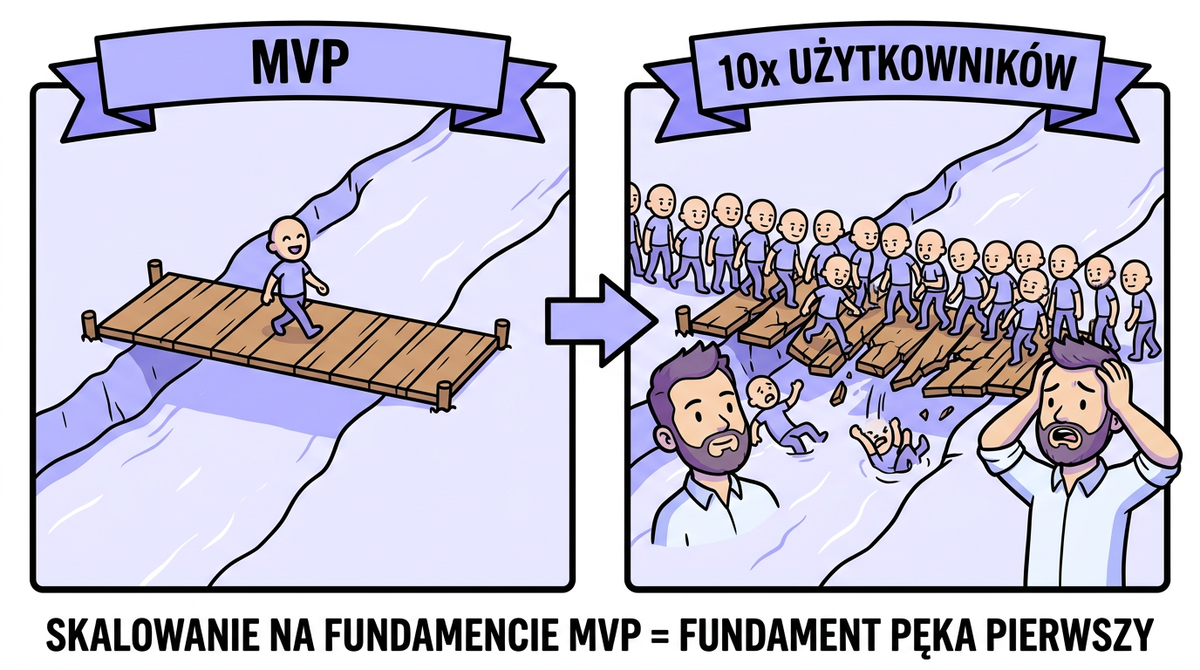
Dług techniczny to nie problem kodu. To model biznesowy.
Większość ludzi myśli o długu technicznym jak o zepsutym samochodzie — coś, co trzeba naprawić, żeby dalej jechać. Błąd. Dług techniczny jest dokładnie jak dług finansowy: ma odsetki. Składane.
Ward Cunningham, który wymyślił ten termin, mówił o świadomym skrócie — bierzesz pożyczkę, żeby szybciej dowieźć. OK, ale pamiętasz, że trzeba będzie spłacić. W praktyce 90% zespołów o tym zapomina. Każdy sprint dokłada trochę skrótów. Odsetki rosną.
Konkretne liczby z raportu TinyMCE i Stripe Developer Coefficient: programiści spędzają 33-42% czasu pracy nad długiem technicznym. Ponad 13 godzin tygodniowo na obsługę starego kodu zamiast pisania nowych funkcji. W skali świata — 85 miliardów dolarów straconej produktywności rocznie.
Ze słownika Noraline: Compounding technical debt — mechanizm, w którym każdy niespłacony skrót w kodzie generuje odsetki w postaci dodatkowego czasu potrzebnego na kolejne zmiany. Matematycznie działa jak lokata w banku: po 3 latach skrót, który zaoszczędził 80 godzin, kosztuje 380 godzin poprawek. Różnica? W banku zarabiasz Ty. W długu technicznym — zarabia chaos.
Fałszywa diagnoza: „potrzebujemy przepisać cały kod"
Widzę to regularnie. Startup ma 2 lata, MVP wypalił, klienci rosną, ale każda nowa funkcja zajmuje 3x dłużej niż powinna. Pierwsza reakcja CTO? „Trzeba przepisać od zera". Wielki refaktor. Sześć miesięcy zablokowanych nowych funkcji. Konkurencja w tym czasie wydaje trzy major releases.
Statystyki z raportu McKinsey 2025: duże przebudowy od zera kończą się sukcesem w mniej niż 30% przypadków. Reszta to „Second-system effect" Fredericka Brooksa — przepisane systemy rosną w złożoność jeszcze szybciej niż oryginalne.
Prawdziwa diagnoza brzmi inaczej: nie potrzebujesz przepisać wszystkiego. Potrzebujesz zidentyfikować 20% kodu, który pochłania 80% czasu utrzymania — i tam celować. Zasada Pareto działa też w architekturze.
Trzy typy długu technicznego (i tylko jeden warto spłacać)
Dług techniczny nie jest jednorodny. Są trzy rodzaje, każdy wymaga innej strategii:
1. Dług świadomy („wiemy, że to będzie bolało"). Celowy skrót, podjęty z otwartymi oczami — „wypuścimy hack teraz, refaktor za miesiąc". To zdrowy dług. Jak hipoteka — bierzesz, bo wiesz, że spłacisz. Harmonogram spłaty istnieje od dnia 1.
2. Dług akumulacyjny („nikt nie pamięta, kiedy to się zepsuło"). Narasta przez lata z tysiąca małych decyzji. Copy-paste, brak testów, nazwy zmiennych typu `tempFix2`. To nowotwór — rośnie cicho, aż pewnego dnia okazuje się, że metastazował wszędzie. Najgorszy rodzaj, bo wymaga archeologii.
3. Dług architektoniczny („to miało być tylko na weekend"). MVP zbudowany jako weekendowy proof-of-concept, który przypadkiem stał się produktem. Monolit, który powinien być mikrousługami. SQLite, który powinien być Postgresem. To jest 90% długu w startupach po MVP. I jedyny, który naprawdę warto refaktorować, bo blokuje skalowanie.

Reguła 15-20%: jak spłacać dług, nie blokując rozwoju
Jakie jest prawdziwe rozwiązanie? Nie wielki refaktor. Nie ignorowanie. Systematyczna spłata.
Netguru w analizie 2025 pokazuje wzorzec: skuteczne zespoły dedykują 15-20% capacity każdego sprintu na spłatę długu. Nie w wielkich refaktorach, tylko w stałym strumieniu małych ulepszeń. Każdy sprint: jedna funkcja duża, dwa fixy w starym kodzie. Zawsze. Bez wyjątków.
Dlaczego nie 50%? Bo wtedy nie rozwijasz produktu. Dlaczego nie 5%? Bo wtedy dług rośnie szybciej niż go spłacasz. 15-20% to matematyczny punkt równowagi — spłacasz więcej, niż zaciągasz, ale produkt dalej idzie do przodu.
Jak to praktycznie wdrożyć? Każdy backlog ma dedykowany track „Technical". Priorytetyzacja: co blokuje najwięcej nowych funkcji? Co pożera najwięcej czasu w debuggowaniu? Co generuje najwięcej bugów raportowanych przez klientów? Tam idzie 15% capacity. Nie mniej.
Roadmap: jak przejść z MVP do produktu
Konkretna mapa, nie filozofia:
Faza 1: Walidacja (MVP). Minimum kodu potrzebne do zweryfikowania hipotezy. Hardcoded configi, manualne procesy backstage, wszystko co trzyma się na sznurku — OK. Jedyna metryka: czy ludzie płacą? Czy wracają? Jeśli nie — nie refaktoruj. Zamknij.
Faza 2: Sharpen (Post-MVP). Masz trakcję. Pierwsze 10-50 płacących klientów. Tutaj tworzysz listę świadomego długu. To, co było „na szybko", czyścisz zanim przyjdzie skalowanie. Kluczowa decyzja: co zostaje z MVP, co idzie do kosza. Pragmatic Coders ma dobry framework: zachowaj dług, który ogranicza funkcje. Wyrzuć dług, który ogranicza skalowanie.
Faza 3: Scale (Produkt). Product-Market Fit osiągnięty, teraz skalujesz. Tu wchodzi reguła 15-20%. Stały, przewidywalny strumień spłat długu. Testy automatyczne. CI/CD. Monitoring. Nie dlatego, że „tak trzeba" — dlatego, że bez tego każda nowa funkcja kosztuje Cię 3x więcej niż powinna.
Różnica między fazami? Faza 1 — tempo > jakość. Faza 2 — selekcja. Faza 3 — jakość > tempo. Błąd większości startupów: stosują reguły Fazy 1 w Fazie 3. Albo reguły Fazy 3 w Fazie 1.
Co robić, gdy dług Cię przerósł
Jesteś w Fazie 3 z kodem z Fazy 1. 40% zespołu pracuje nad starymi bugami. Każdy release wiąże się z modlitwą. Ludzie z zespołu odchodzą, bo nie chcą pracować z tym kodem.
Trzy kroki, w tej kolejności:
- Audyt, nie refaktor. Zrób listę wszystkich komponentów. Dla każdego: ile bugów w ostatnim kwartale, ile czasu na zmiany, ile developerów umie z nim pracować. Kod, który jest stary ale działa — zostaw. Kod, który generuje 80% problemów — wyceluj.
- Refaktor strażujący. Wybierz 1-2 komponenty z listy audytowej. Zaplanuj w sprincie. Nie „przepiszmy wszystko". Tylko to, co blokuje najwięcej.
- Zamroź nowe funkcje w tym obszarze. Bez tego będziesz refaktorował coś, co równocześnie rośnie. Syzyf. Komunikacja z biznesem: „przez 2 sprinty w tym module nie dodajemy funkcji, ale potem tempo wzrośnie 2x".
Unikaj klasycznej pułapki: Sunk cost fallacy. „Już zainwestowaliśmy tyle w ten kod, że nie możemy go wyrzucić". Możesz. Czasem powinieneś. Ale decyzja musi być świadoma — nie emocjonalna.
Sygnały, że Twoje MVP jest gotowe do fazy 2
Sprawdź:
- Retencja w 30 dniu > 40%. Ludzie wracają, nie tylko się zapisują.
- NPS > 30. Ktoś faktycznie poleca Twój produkt.
- Kilka organicznych klientów. Nie tylko ci, których znasz osobiście.
- Pierwszy klient zapłacił więcej niż 30 PLN. Wolicjonalna decyzja, nie „spróbujmy za 9 zł".
- Widzisz wzorce w use case. Nie każdy używa inaczej. Są 2-3 sposoby, którymi ludzie osiągają wartość.
Jeśli nie masz trzech z pięciu — jesteś wciąż w Fazie 1. Nie refaktoruj. Waliduj dalej lub zmień produkt. Jeśli masz wszystkie pięć — czas zacząć sprzątać. Nie przepisywać — sprzątać.
Co zrobić w poniedziałek
Niezależnie od tego, w jakiej fazie jesteś:
- Zrób mapę długu. 30 minut z zespołem. Zapisz wszystkie miejsca w kodzie, o których ktoś mówi „to trzeba będzie kiedyś poprawić". Zlicz. Jeśli masz więcej niż 20 pozycji — masz problem systemowy, nie punktowy.
- Wyznacz 15% capacity. W najbliższym sprincie. Nie 20%, nie 10%. 15%. Na co? Na najczęściej powracające bugi z ostatniego miesiąca. Tydzień pracy. Zobacz, jak zmieni się tempo.
- Rozróżnij trzy typy długu. Świadomy, akumulacyjny, architektoniczny. Jakiego masz najwięcej? To Twój priorytet numer 1.
- Zidentyfikuj 20%, które pożera 80%. Jeden-dwa komponenty. Tam celuj.
Nie próbuj wszystkiego naraz. Pisałem o długu operacyjnym — te same zasady dotyczą długu technicznego. Wielki refaktor umiera. Systematyczna spłata działa.
Napisz: REFAKTOR — prześlę Ci szablon audytu długu technicznego, którego używam u klientów. 5 pytań, 30 minut, konkretne priorytety do backlogu.
Najczesciej zadawane pytania
Dług techniczny to koszt przyszłych zmian w kodzie wynikający ze skrótów podjętych wcześniej. Całkowite unikanie go jest nierealne — czasem świadomie wybierasz szybsze dostarczenie za cenę późniejszego refaktoru. Kluczowa zasada: każdy zaciągnięty dług musi mieć plan spłaty. Bez tego odsetki rosną składane — po 3 latach skrót, który oszczędził 80 godzin, może kosztować 380 godzin poprawek.
MVP (Minimum Viable Product) to eksperyment służący walidacji hipotezy biznesowej — sprawdza, czy ktoś chce płacić za Twoje rozwiązanie. Produkt to system zbudowany do skalowania, z fundamentami pod tysiące użytkowników. 67% startupów upada, bo buduje produkt, którego nikt nie chce — MVP ma temu zapobiec. Błędem jest traktowanie MVP jak fundamentu produktu; MVP powinien być testem, nie szkieletem.
Przepisywanie od zera kończy się sukcesem w mniej niż 30% przypadków — to statystyka McKinsey 2025. Lepiej refaktorować wybiórczo. Zasada Pareto: zidentyfikuj 20% kodu, które pochłania 80% czasu utrzymania i tam uderz. Przepisanie całego systemu blokuje rozwój na miesiące, a 'second-system effect' powoduje, że nowy system często jest bardziej złożony niż oryginalny.
Sprawdzona proporcja to 15-20% capacity każdego sprintu. Mniej niż 10% — dług rośnie szybciej niż go spłacasz. Więcej niż 30% — blokujesz rozwój produktu. 15-20% to matematyczny punkt równowagi: systematycznie redukujesz dług, nie zatrzymując nowych funkcji. Kluczem jest stała praktyka, a nie wielkie refaktoringi raz na rok — te zwykle kończą się porażką lub porzuceniem.
Trzy typy: (1) Świadomy — celowy skrót z planem spłaty, zdrowy jak hipoteka; (2) Akumulacyjny — narasta latami z tysiąca małych decyzji, najtrudniejszy w diagnozie; (3) Architektoniczny — MVP zbudowany jako weekend project, który stał się produktem (monolit zamiast mikrousług, niewłaściwa baza danych). Dług architektoniczny to 90% problemów w startupach po MVP i jedyny, który naprawdę blokuje skalowanie.
Pięć sygnałów: retencja w 30. dniu powyżej 40%, NPS powyżej 30, kilku organicznych klientów (nie tylko znajomi), pierwszy klient płacący więcej niż 30 PLN oraz wyraźne wzorce w sposobach korzystania z produktu. Minimum trzy z pięciu muszą być spełnione. Bez tego jesteś wciąż w fazie walidacji — refaktoryzacja na tym etapie to marnowanie zasobów, bo i tak możesz musieć pivotować.
Sygnały alarmowe: każda nowa funkcja zajmuje 2-3x więcej czasu niż powinna; 30-40% czasu zespołu idzie na fixy bugów; developerzy odchodzą, bo 'ten kod jest nie do pracy'; release wiąże się z modlitwą zamiast procedurą. Jeśli masz przynajmniej dwa z tych symptomów, dług przeszedł z poziomu operacyjnego na strategiczny. Wtedy nie wystarczy 15% capacity — potrzebujesz targeted refactor najbardziej problematycznych komponentów.
Szymon Mojsak
Ekspert automatyzacji procesów biznesowych oraz specjalista ds. HR z wieloletnim doświadczeniem w wdrażaniu zaawansowanych rozwiązań IT w obszarze zarządzania zasobami ludzkimi. Jako współwłaściciel RCPonline, lidera rynku systemów rejestracji czasu pracy, łączy dogłębną wiedzę technologiczną ze zrozumieniem wymogów prawnych oraz specyfiki branży HR. Regularnie tworzy treści i analizy w oparciu o aktualne standardy branżowe, koncentrując się na bezpieczeństwie, skuteczności i transparentności procesów, co przekłada się na realną wartość dla klientów biznesowych.
→ Więcej o autorze
Ładowanie komentarzy...