
Spędziłeś godzinę na pisaniu promptu. Dodałeś kontekst, przykłady, instrukcje krok po kroku. ChatGPT odpowiedział idealnie. Następnego dnia zadałeś to samo pytanie — i dostałeś zupełnie inną odpowiedź. Bo model nie pamięta. Nie zna Twojej firmy. Nie wie, że „klient premium" u Ciebie oznacza coś innego niż w podręczniku marketingu.
Prompt engineering ma sufit. I właśnie w niego uderzasz. Jak pisze Neo4j: „Prompt engineering ma wyraźne limity dla czegokolwiek poza prostymi chatbotami — modele zapominają kluczowe szczegóły, używają narzędzi nieprawidłowo lub halucynują informacje". Rozwiązanie nie leży w lepszym prompcie. Leży w lepszym kontekście.
Key Takeaways:
- Prompt engineering to optymalizacja pytania. Context engineering to budowa systemu, który wie — zanim zapytasz
- Rynek RAG (Retrieval-Augmented Generation) wzrośnie z 2,3 mld do 11 mld USD do 2030 — bo firmy potrzebują AI z ich danymi
- Firmy raportują 40-60% szybsze rozwiązywanie problemów gdy AI ma semantyczny dostęp do bazy wiedzy
- Większe okno kontekstowe nie rozwiązuje problemu — accuracy spada już przy 32 000 tokenów
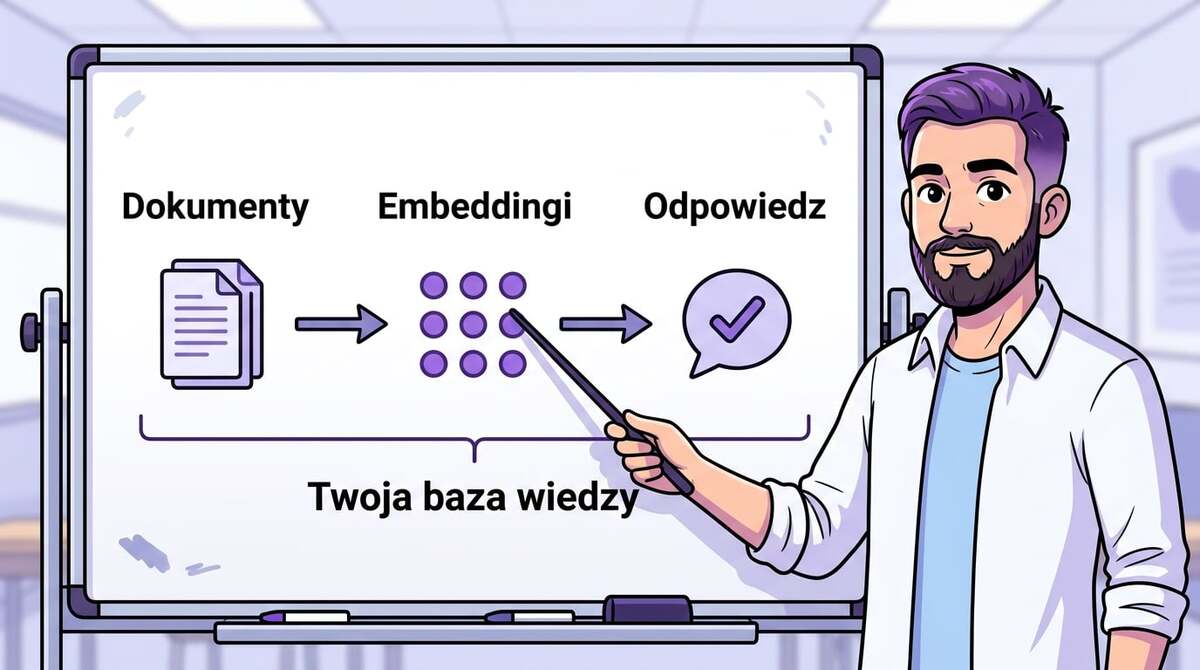
- 5 kroków: zbierz dokumenty → podziel na chunki → zamień na embeddingi → zapisz w bazie wektorowej → podłącz do LLM
Prompt engineering umarł. Niech żyje context engineering
Branża przeżywa zwrot. W 2026 roku rozmowa przeniosła się z „jak lepiej napisać prompt" na „jak dostarczyć AI właściwy kontekst we właściwym momencie". To fundamentalna zmiana — z optymalizacji pytania na budowę infrastruktury wiedzy.
Prompt engineering to jak krzyczenie głośniej do osoby, która nie mówi w Twoim języku. Context engineering to nauczenie jej Twojego języka.
Różnica? Prompt: „Jesteś ekspertem od marketingu B2B SaaS. Napisz email do CMO firmy produkcyjnej z branży automotive...". Context: system, który automatycznie wie kim jest Twój klient, jakie maile działały w przeszłości, jaki ton preferuje ta branża — i generuje odpowiedź bez 500 słów instrukcji.

Okno kontekstowe: więcej nie znaczy lepiej
„GPT-4 ma 128K tokenów kontekstu! Wrzucę całą dokumentację!" Brzmi logicznie? Badania pokazują, że accuracy modeli zaczyna spadać już przy 32 000 tokenów — nawet przy ekstremalnie prostych zadaniach wyszukiwania. Im więcej wrzucisz, tym gorzej model rozpoznaje co jest istotne.
To jak dać stażyście dostęp do 50 segregatorów i powiedzieć „znajdź odpowiedź". Nie potrzebuje 50 segregatorów. Potrzebuje jednego właściwego dokumentu, otwartego na właściwej stronie.
Ze słownika Noraline: RAG (Retrieval-Augmented Generation) — architektura, w której AI przed wygenerowaniem odpowiedzi najpierw wyszukuje relevantne fragmenty z Twojej bazy wiedzy. Zamiast polegać na tym, co model „zapamiętał" podczas treningu, RAG podaje mu świeże, specyficzne dane z Twoich dokumentów. Efekt: mniej halucynacji, więcej faktów, odpowiedzi dopasowane do Twojego biznesu.
Rynek RAG: z 2,3 miliarda do 11 miliardów. Dlaczego?
Grand View Research prognozuje wzrost rynku RAG z 2,33 mld USD w 2025 do 11 mld USD do 2030 — CAGR 49,1%. Nie dlatego, że to modna technologia. Dlatego, że firmy odkryły, że generyczne AI bez kontekstu firmowego jest bezużyteczne w produkcji.
Według Data Nucleus, 30-60% przypadków użycia AI w przedsiębiorstwach wymaga RAG — wszędzie tam, gdzie potrzebna jest wysoka dokładność, przejrzystość źródeł i dostęp do firmowych danych. Sektory regulowane (healthcare, finanse, prawo) prowadzą adopcję, bo nie mogą sobie pozwolić na halucynacje.
A firmy raportują 40-60% szybsze rozwiązywanie problemów gdy agenci wsparcia mają semantyczny dostęp do bazy wiedzy zamiast ręcznego przeszukiwania FAQ.
5 kroków budowy bazy wiedzy dla AI
Bez buzzwordów. Oto jak to zrobić w praktyce.
Krok 1: Zbierz dokumenty. Wszystko, co Twoja firma wie: procesy, FAQ, maile wzorcowe, dokumentacja produktowa, notatki ze spotkań, umowy szablonowe. Nie filtruj na tym etapie — zbieraj. Format nie ma znaczenia: PDF, Word, Markdown, Google Docs, Notion, nawet transkrypcje rozmów.
Krok 2: Podziel na chunki. Optymalne chunki to 200-500 słów. Za duże — embedding „rozmywa" ważne szczegóły. Za małe — traciasz kontekst. To jak krojenie chleba: kromki, nie okruszki i nie cały bochenek.
Krok 3: Zamień na embeddingi. Każdy chunk przechodzi przez model embeddingowy (np. OpenAI text-embedding-3-small — 1536 wymiarów) i zamienia się w wektor liczb. Ten wektor reprezentuje „znaczenie" tekstu — dwa chunki o podobnej tematyce będą miały podobne wektory, nawet jeśli używają innych słów.
Krok 4: Zapisz w bazie wektorowej. Pinecone, Weaviate, pgvector, Qdrant — wybierz według budżetu i skali. Dla startu pgvector (rozszerzenie Postgresa) wystarczy i jest darmowe. Nie potrzebujesz osobnej infrastruktury na dzień pierwszy.
Krok 5: Podłącz do LLM. Gdy użytkownik zadaje pytanie, system: (a) zamienia pytanie na embedding, (b) wyszukuje najbardziej podobne chunki w bazie, (c) podaje je jako kontekst do LLM, (d) LLM generuje odpowiedź na podstawie Twoich danych, nie swoich halucynacji.
Czego 63,6% firm robi źle
Przegląd systematyczny MDPI pokazuje, że 63,6% implementacji RAG używa modeli GPT, a 80,5% polega na standardowych frameworkach retrieval (FAISS, Elasticsearch). Gdzie problem? W trzech miejscach.
Brak hybrydowego wyszukiwania. Samo wyszukiwanie wektorowe świetnie łapie szerokie koncepcje, ale „gubi" konkretne nazwy produktów, numery zamówień czy akronimy branżowe. Rozwiązanie: hybrid search — połączenie wektorowego (semantycznego) z keyword search (dokładnym). Jedno bez drugiego to pół systemu.
Brak świeżości danych. Wiedza firmowa zmienia się codziennie. Jak pisałem o pułapkach automatyzacji — system zbudowany na starych danych będzie generował stare odpowiedzi. Automatyczny refresh — dziennie lub częściej dla krytycznych systemów.
Brak kontroli dostępu. Jeśli stażysta może zapytać AI o wynagrodzenia zarządu, masz problem. Filtrowanie wyników wyszukiwania PRZED podaniem ich do modelu — nie po.
Prompt engineering nadal ma sens. Ale nie sam
Nie mówię, żebyś przestał pisać dobre prompty. Prompt engineering + baza wiedzy to nie albo/albo. To warstwy. Prompt mówi modelowi JAK odpowiadać (ton, format, długość). Baza wiedzy mówi CO wie (fakty, dane, kontekst).
Analogia: prompt to sposób, w jaki mówisz do eksperta. Baza wiedzy to wykształcenie tego eksperta. Możesz idealnie sformułować pytanie — ale jeśli „ekspert" nie zna Twojej firmy, dostaniesz generyczną odpowiedź z podręcznika.
Pisałem o agentach AI — agent bez bazy wiedzy to agent, który halucynuje z pewnością siebie. Agent Z bazą wiedzy to agent, który cytuje Twoje dokumenty.
Od czego zacząć jutro rano
Nie buduj idealnego systemu. Zbuduj minimalny. Oto przepis na pierwszy tydzień:
Dzień 1: Zbierz 20-30 najczęściej używanych dokumentów (FAQ, procesy, szablony). Eksportuj do Markdown lub plain text.
Dzień 2-3: Podziel na chunki (200-500 słów), wygeneruj embeddingi (OpenAI API — koszt: grosze). Zapisz w pgvector lub Pinecone free tier.
Dzień 4-5: Podłącz prosty interfejs (Streamlit, custom chat, albo nawet skrypt CLI). Pytanie → wyszukiwanie → kontekst → odpowiedź LLM.
Tydzień 2: Testuj z zespołem. Zbieraj feedback. Które odpowiedzi są dobre? Które halucynują? Dodaj brakujące dokumenty. Popraw chunking.
To nie jest projekt na kwartał. To jest projekt na tydzień, który potem rośnie. Jak każda dobra automatyzacja — zaczyna od jednego procesu i skaluje się z danymi.
AI, która zna Twój biznes — to nie science fiction
Rynek mówi jasno: w 2026 roku RAG przeszedł z fazy eksperymentów do infrastruktury krytycznej. Nie dlatego, że jest modny. Dlatego, że firmy odkryły prostą prawdę: generyczny AI bez Twoich danych to drogi chatbot. AI z Twoją bazą wiedzy to cyfrowy ekspert od Twojego biznesu.
Różnica między „ChatGPT powiedział mi coś generycznego" a „nasz system odpowiedział na podstawie naszej dokumentacji z linkiem do źródła" — to różnica między zabawką a narzędziem. Nie utrzymuj generycznego AI tylko dlatego, że już za niego płacisz. Zainwestuj w kontekst.
Chcesz zbudować bazę wiedzy dla AI w swojej firmie, ale nie wiesz od czego zacząć? Napisz: AUDYT — pomogę Ci zmapować dokumenty, wybrać architekturę i postawić pierwszy prototyp w tydzień.
Najczesciej zadawane pytania
Prompt engineering to optymalizacja samego pytania do AI — lepsze sformułowanie, dodanie przykładów, instrukcji. Context engineering to budowa infrastruktury wiedzy, która automatycznie dostarcza AI właściwe dane z Twojej firmy. Prompt mówi JAK odpowiadać, baza wiedzy mówi CO wie. Jedno bez drugiego daje albo ładnie sformatowane halucynacje, albo surowe dane bez formy.
RAG (Retrieval-Augmented Generation) to architektura, w której AI przed wygenerowaniem odpowiedzi wyszukuje relevantne fragmenty z Twojej bazy wiedzy. Zamiast polegać na ogólnej wiedzy modelu, RAG podaje mu świeże, specyficzne dane z Twoich dokumentów. Efekt: mniej halucynacji, odpowiedzi oparte na faktach firmowych, z możliwością wskazania źródła. Rynek RAG rośnie o 49% rocznie do 11 mld USD w 2030.
Minimalny prototyp można postawić w tydzień, prawie za darmo: pgvector (darmowe rozszerzenie Postgresa) jako baza wektorowa, OpenAI API do generowania embeddingów (grosze za tysiące dokumentów), prosty interfejs w Streamlit. Koszty rosną ze skalą — dedykowane bazy wektorowe jak Pinecone zaczynają od free tier. Pierwszy działający system to nie projekt na kwartał, to projekt na tydzień.
Badania pokazują, że accuracy modeli spada już przy 32 000 tokenów, nawet przy prostych zadaniach wyszukiwania. Wrzucenie całej dokumentacji do kontekstu nie pomaga — model gorzej rozpoznaje co jest istotne w morzu danych. RAG rozwiązuje to podając modelowi tylko te 3-5 najrelevantniejszych fragmentów, zamiast 50 segregatorów naraz.
Dzień 1: zbierz 20-30 najczęściej używanych dokumentów (FAQ, procesy, szablony). Dni 2-3: podziel na chunki 200-500 słów, wygeneruj embeddingi. Dni 4-5: podłącz prosty interfejs czatowy. Tydzień 2: testuj z zespołem, zbieraj feedback, dodawaj brakujące dokumenty. Kluczowa zasada: zacznij mały, iteruj szybko, nie buduj idealnego systemu od razu.
Trzy główne: brak hybrydowego wyszukiwania (samo wektorowe gubi nazwy produktów i akronimy — trzeba łączyć z keyword search), brak odświeżania danych (wiedza firmowa zmienia się codziennie, a stare embeddingi dają stare odpowiedzi), brak kontroli dostępu (AI nie powinno ujawniać danych HR stażyście). 63% implementacji polega na standardowych frameworkach bez tych zabezpieczeń.
Szymon Mojsak
Ekspert automatyzacji procesów biznesowych oraz specjalista ds. HR z wieloletnim doświadczeniem w wdrażaniu zaawansowanych rozwiązań IT w obszarze zarządzania zasobami ludzkimi. Jako współwłaściciel RCPonline, lidera rynku systemów rejestracji czasu pracy, łączy dogłębną wiedzę technologiczną ze zrozumieniem wymogów prawnych oraz specyfiki branży HR. Regularnie tworzy treści i analizy w oparciu o aktualne standardy branżowe, koncentrując się na bezpieczeństwie, skuteczności i transparentności procesów, co przekłada się na realną wartość dla klientów biznesowych.
→ Więcej o autorze
Ładowanie komentarzy...